Enzymes are highly specific in which molecules they bind to. Here, we will learn why.
Prostaglandins and Leukotrienes are major forms of human hormones. They are allosteric up-regulators of hormone response, at sub-nanomolecular concentrations.
Prostaglandins and Leukotrienes control reactions such as asthma, inflammation, pain, gastric function, reproduction and gender.
These hormones are all synthesised from one common precursor: arachidonic acid. There only difference between these biosynthesis pathways is the type of enzyme used. The enzyme selects for the particular product.
Arachidonic Acid Pathways
Prostaglandin PGG2 is synthesised via cyclooxygenase and O2. Leukotriene LTB4 is synthesised via lipoxygenase and O2.
These oxidation reactions occur via catalysis, either with a metal co-factor or a tyrosine side-chain, to overcome the free radical involved in the catalytic process.
Lipoxygenase uses an Fe2+ co-factor at the enzyme active site to propagate the REDOX chemistry chain involved in leukotriene synthesis. The co-factor binds the oxygen and loses an electron. Through the electron transfer process, the co-factor produces a super oxide radical anion; a stable species. A hydrogen atom is then pick from the arachidonic acid substrate to produce a substrate radical; converting the super oxide radical anion to a hydrogen peroxide anion. This hydrogen peroxide anion can undergo a reverse electron transfer to produce reactive arachidonic acid radical (a hydrogen peroxide radical) – henceforth, creating hydrogen peroxide and reducing it to the associated alcohol.
Cyclooxygenase has no co-factor – rather, it uses the tyrosine side-chain at the enzyme active site. The tyrosine side-chain oxygen’s centered radical pulls a hydrogen atom off the arachidonic acid to produce an arachidonic acid radical. This radical and oxygen are then combined to produce a peroxy radical, pulling the hydrogen atom back off tyrosine; creating an arachidonic acid hydrogen peroxide and regenerating the side-chain radical, before reducing it to its associated alcohol. In this reaction, however, the intermediates can undergo rearrangement cyclisation – making it slightly more complicated than the lipoxygenase process.
Enzymes control these processes via lowest energy pathways. The enzymes selectively lower the transition state energy along different pathways to synthesise their desired product. Enzyme seek the energy pathway of least resistance.
Arachidonic acid reacts at the C7 radical on leukotriene, whilst it reacts at the C13 radical on prostaglandin. This is because the hydrogen extraction is determined by the geometry of the enzyme active site.
Arachidonic acid, at the active site, folds itself in a way to conformationally fit to its associated enzyme.
Enzyme regioselectivity and stereochemistry is determined by the enzyme active site geometry.
That is why taking medication/”vitamins” without talking to a doctor first can be detrimental. Taking arachidonic acid tablets can overall for detrimental for the body with negative side-effects. An over-production of arachidonic acid can result in blood clotting.
Enzyme inhibitors for cyclooxygenase enzymes can either be irreversible, covalent inhibitors, competitive inhibitors, or allosteric, non-irreversible inhibitors.
COX inhibitors ibuprofen and naproxen are competitive inhibitors that work via entropy. They compete with cyclooxgyenase, and prevent the synthesis of prostaglandin. As prostaglanding causes pain and inflammation, ibuprofen and naproxen can be used to treat such pain.
Aspirin is an irreversible inhibitor, as the COX residue at the active site displaces the acetyl group to a serine on the enzyme site – blocking the enzyme of the COX – and creates a covalent bond.
Celebrex and toricox are allosteric inhibitors, that do not resemble the substrate. There is no indication that these compounds will bind to the active site.
Penicillium is a genus of fungi that plays a vital role in the pharmaceutical and medicinal industries. In 1929, Alexander Fleming, a bacteriologist in London, published a paper detailing an isolated Penicillium mould. He named the active agent of this mould ‘penicillin’, and determined that penicillin has an anti-bacterial effect on multiple pathogens.
Although Fleming is credited with the discovery of penicillin, it is likely that penicillin has been in use since prehistoric times. Ancient Egypt and Ancient Greece, famously, each used an enormous assortment of such moulds for an arrangement of medicinal uses.
The versatile pharmacological effect of the fungi is due to their unique structure.
Penicillin General Structure
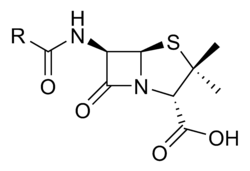
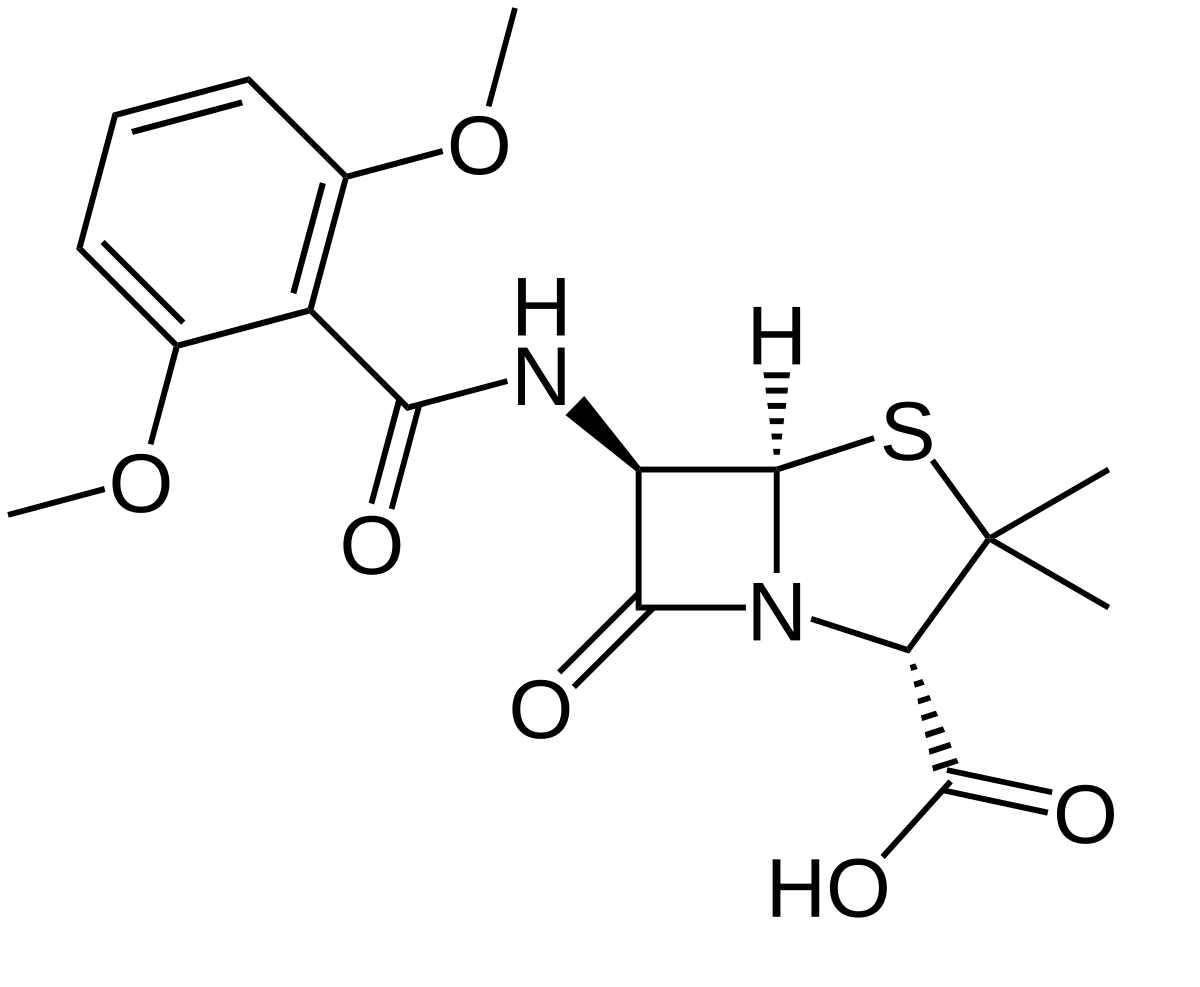
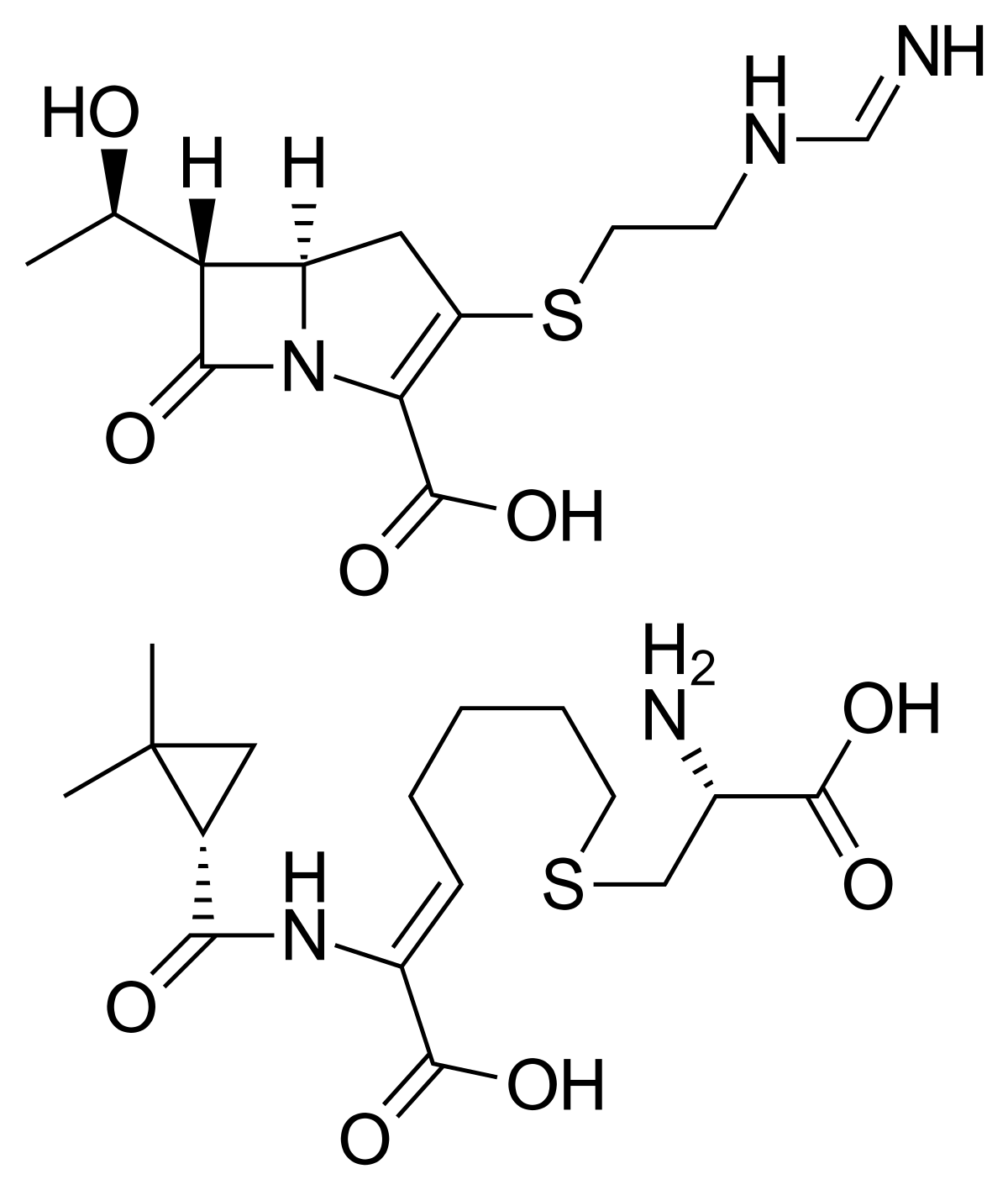
Penicillin comes in various forms, such as Penicillin G (benzylpenicillin) and Penicillin V (phenoxymethylpenicillin). Other β-lactam antibiotics include cephalosporins. The characteristic feature of all penicillins and cephalosporins is the 4-membered cyclic amide, or β-lactam ring. The ring has a high bond strain of 90° – making it a highly reactive molecule once the strain is released.
Penicillin kills bacteria through the inhibition of the enzyme DD-transpeptidase via the β-lactam ring.
DD-transpeptidases synthesise bacterial cell walls – by inhibiting this enzyme, new cell wall formation is also inhibited; the bacterial cell wall becomes vulnerable to external forces and subsequently dies.
DD-Transpeptidase
Penicillin compounds highly resemble D-Ala-D-Ala amides. Hence, when a penicillin binds to the DD-transpeptidases, the serine will attack the amide bond of the β-lactam group, and an ester will form. The new five-membered ring henceforth blocks further binding to the enzyme active site.
Penicillin vs D-Ala-D-Ala
The detection of this particular mechanism within the penicillin compounds has significantly changed the process of infectious disease treatment; bacterial diseases can be combatted. Modern medicine has been refined to reproduce the process within the Penicillium genus responsible for medicinal value. This has led to a large, industrial-level development of antibiotics.
Antibiotics are drugs that help stop infections caused by bacteria. For example, Penicillin G was the original penicillin ‘discovered’ by Fleming. It came into commercial use in 1942, and was famously used for treatment during WWII. Penicillin G antibiotics treat a wide variety of bacterial infections, including diphtheria, pneumonia, gas gangrene and tetanus. It is mostly administered via injection.
Biosynthesis of the β-lactam antibiotics begins with the biosynthesis of the common precursor amino acids: a homologue of glutamic acid, an L-cysteine and a D- valine. These amino acids link via peptide bonds. An isopenicillin N synthetase then catalyses the cyclisation of the Arnstein peptide through to give isopenicillin N via REDOX reaction.
After this, a peptidase cleaves the amide bond to produce 6-aminopenicillicacid (6-APA). The REDOX co-factors in this reaction, Fe2+ and O2, assist in this cleavage. Acylating the resulting nitrogen compound leads to the development of the penicillin antibiotic.
Cephalosporins are synthesised with cephalosporin synthetase. The continuing biosynthesis follows the same pathway as penicillins.
Penicillin G Synthesis
Unfortunately, with the use of antibiotics, comes the development of antibiotic resistant-bacteria. Causes of antibiotic resistance vary, however, are predominantly the result of over-prescription, over-use, and patients not finishing their course. Bacteria, such as E. coli, have evolved new mechanisms to overcome the inhibitory effects of β-lactamase inhibitors. There are several mechanisms bacteria use, however, a common one is drug inactivation or modification – some penicillin-resistant bacteria have developed the ability to enzymatically deactivate penicillin.
β-Lactamases are enzymes produced by some bacterial cell walls that have the ability to convert penicillin to the biologically inactive ‘penicilloic’, by adding an acetyl or phosphate group to the specific site on the antibiotic. This effectively disrupts the functioning of the antibiotic; causing the bacteria to be resistant to the β-lactam ring attack.
β-lactamase
This is a very effective mechanism, as not only do β-lactamases turn over substrate at ~2000/sec, the outer-membrane of the gram-negative, and peptidoglycan layer for the gram-positive bacteria, filter the penicillin getting through to the penicillin binding protein. The net result of this, is that β-lactamases are a common form of antibiotic resistance.
Gram-Negative vs Gram-Positive Bacterial Cell Walls
This resistance has the potential to have dire effects on the health industry, and furthermore, the overall population’s health – as bacteria overcoming such inhibitors renders the preferred use of medicinal penicillin invalid.
Many strategies to fight bacterial resistance have been developed. β-lactamase inhibitors, such as clavulanate, have the ability to bind to penicillin-binding proteins and overcome antibiotic resistance in bacteria that secrete β-lactamase. To put simply, β-lactamase inhibitors are able to inhibit β-lactamase. By combining β-lactamase inhibitors with penicillin in the form of a drug, β-lactamase can be overcome, and the challenges of antibiotic resistance can be more readily tackled. Further preventative measures, such as prescribing antibiotics only when necessary, limiting the use of antibiotics, and education patients to completely finish their course, can also help prevent the development of antibiotic resistance.
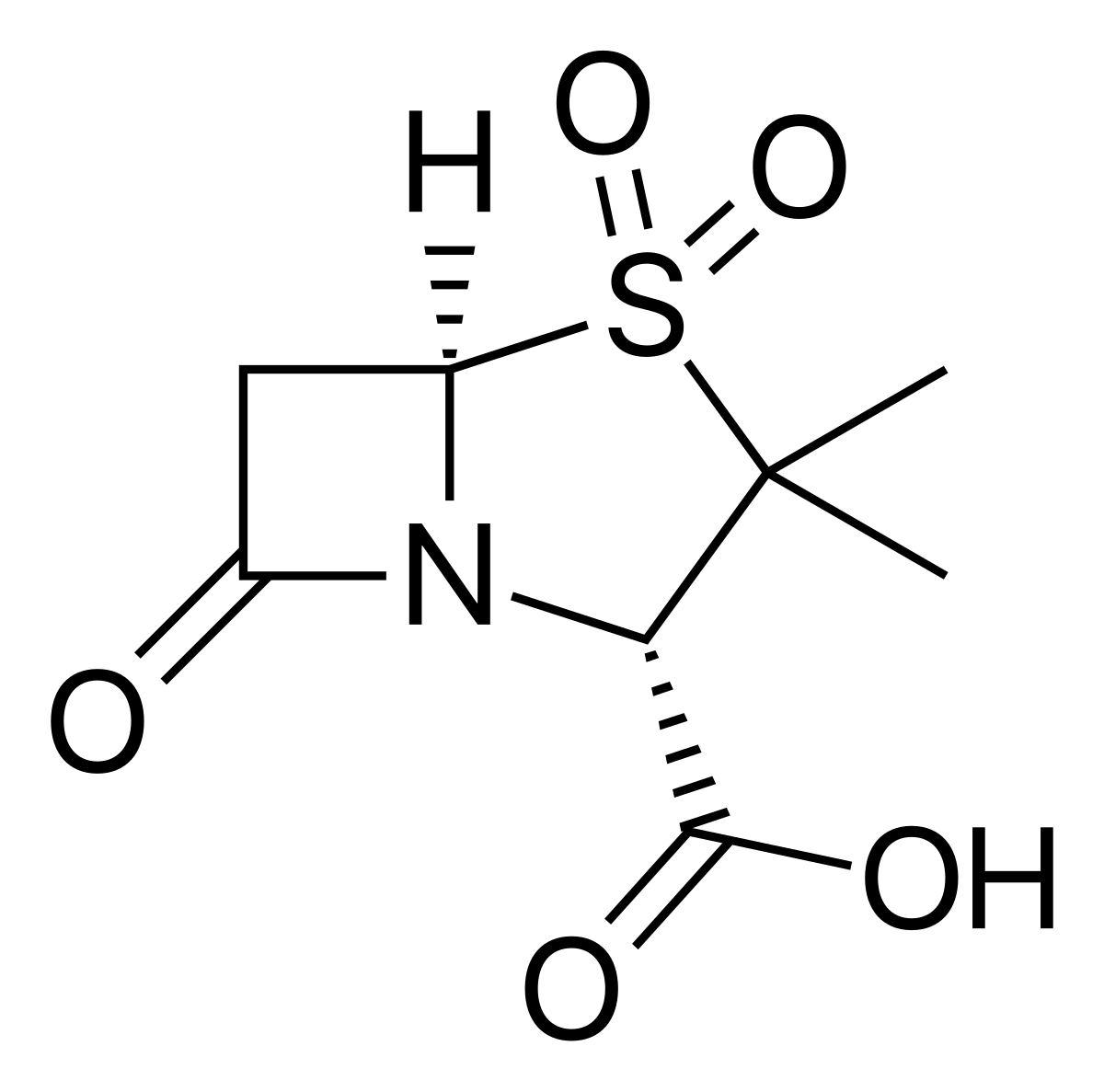
When penicillin resistance first came about, the initial response was to utilise cephalosporins. The reason why cephalosporins worked is related to their double bond in their six-membered ring.
Cephalosporin Structure
When the β-lactam antibiotics react with the β-lactamase, an ester is formed, and the the electrons of the cephalosporin core nitrogen are delocalised over the double bond to create a weak amine; the base catalysis of the ester hydrolysis is reduced. However, resistance was quickly developed against this.
Methicillin and flucloxacillin were the next to be developed.
Methicillin
Flucloxacillin
Methicillin and flucloxacillin have bulky, hydrophobic substituent, at the top left position of the β-lactam. This substituent can fit into the binding pocket of the penicillin binding proteins better than the binding pocket of the β-lactamase enzymes. This is because the β-lactamase enzymes are less hydrophobic and allow water through to hydrolyse esters. The penicillin binding proteins petition more effectively. However, further β-lactamase mutation then occurred – leading to more resilience.
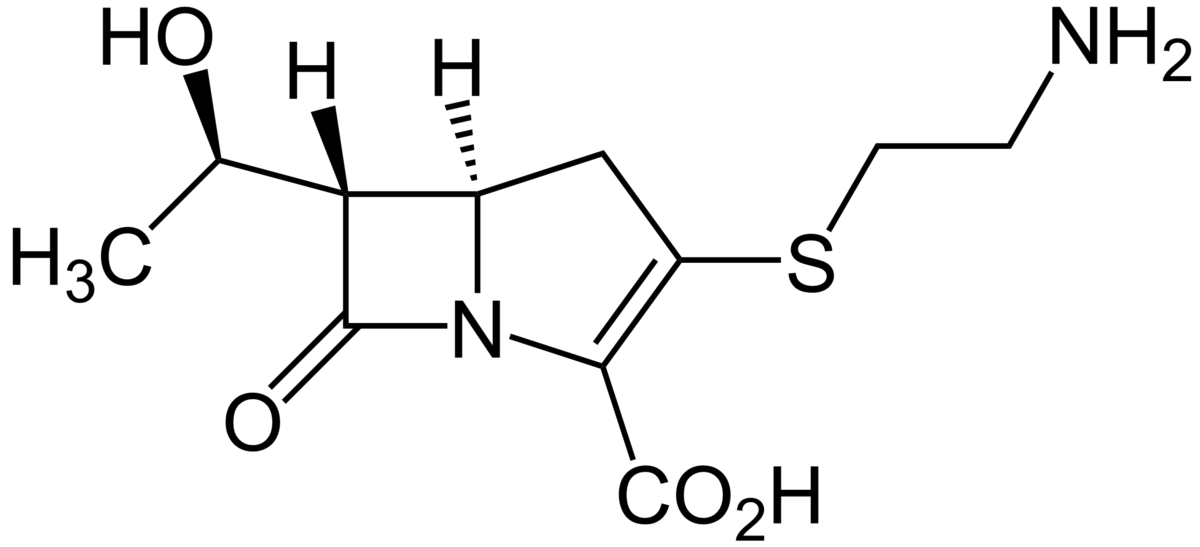
Thienamycin was then developed.
Thienamycin
Thienamycin is the 5th generation antibiotic. It functions similarly to the cephalosporin. Thienamycin inhibit the β-lactamase enzyme by forming an ester intermediate, but are less resistant to hydrolysis. The problem with thienamycin is that the active groups involved destroy the antibiotic itself. Henceforth, thienamycin was modified.
The modified products of thienamycin were imipenem and cilastatin.
Imipenem (top) Cilastatin (bottom)
By tying up the top-left amino group of the thienamycin, the compounds become stable. However, imipenem is removed in the kidneys of patients. It is recognised by the dehydropeptidase enzyme that removes dehydroamino acids. Cilastatin was henceforth developed to inhibit the dehydropeptidase. Both drugs were then combined to inhibit the β-lactamase. However, an issue with combining these drugs is that their effectiveness varies depending on their bioavailability across the gastro-intestinal tract. The compounds have different polarity and distribution across the body, and henceforth are rarely administered as an antibiotic.
Sulbactam is the sixth generation antibiotic to have been developed.
Sulbactam
Sulbactam has no side-chain in the top-left position of the β-lactam ring. Sulbactam works because of its charged substituent; a good leaving group. Base hydrolysis of the ester does not occur. Sulbactam strays from equilibirum between an amine and imine, making it more effective. However, it does not bind to the penicillin binding proteins due to its lack of substituent – and must be combined with another β-lactam antibiotic.
Unasyn is the combination of sulbactam and ampicillin. However, like before, these compounds vary drastically in their polarity and bioavailability – hence, sultamicillin was developed.
Sultamicillin
Sultamicillin effectively ties the two products together, allowing the compounds to transfer into the bloodstream at relatively the same rate and concentration.
Clavulanic acid is the seventh generation response to bacteria.
Clavulanic Acid
Clavulanic acid reacts selectively with the β-lactamase enzymes. It opens the β-lactam ring to form an ester intermediate, which can undergo base catalysed hydrolysis to cleave and release the material. Clavulanic acid has an inolate leaving group, which generates an imine. Following this, an irreversible reaction occurs, wherein an inhibitor enzyme attaches. It is a “suicide substrate, irreversible inhibitor”.
Clavulanic acid must be combined with an antibiotic to work effectively. Augmentin is the combination of clavulanic and amoxycillin.
Augmentin Tablets
Drugs of last resort are vancomycin (used by injection) and linezolid (used for long-term infections). These drugs have serious side-effects and are quite unstable, hence, are only used in hospital circumstances.
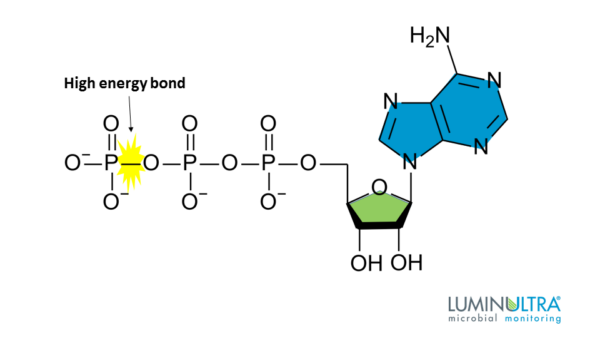
ATP is the “energy currency” of cells. In free solution, nucleophiles cannot get past the negative oxygens in the molecule. However, when ATP binds at an enzyme active site, it coordinates to magnesium. These oxygens subsequently neutralise, become susceptible to a nucleophilic attack.
Phosphates, such as ATP, have a special stability in solution, and a special reactivity once bound.
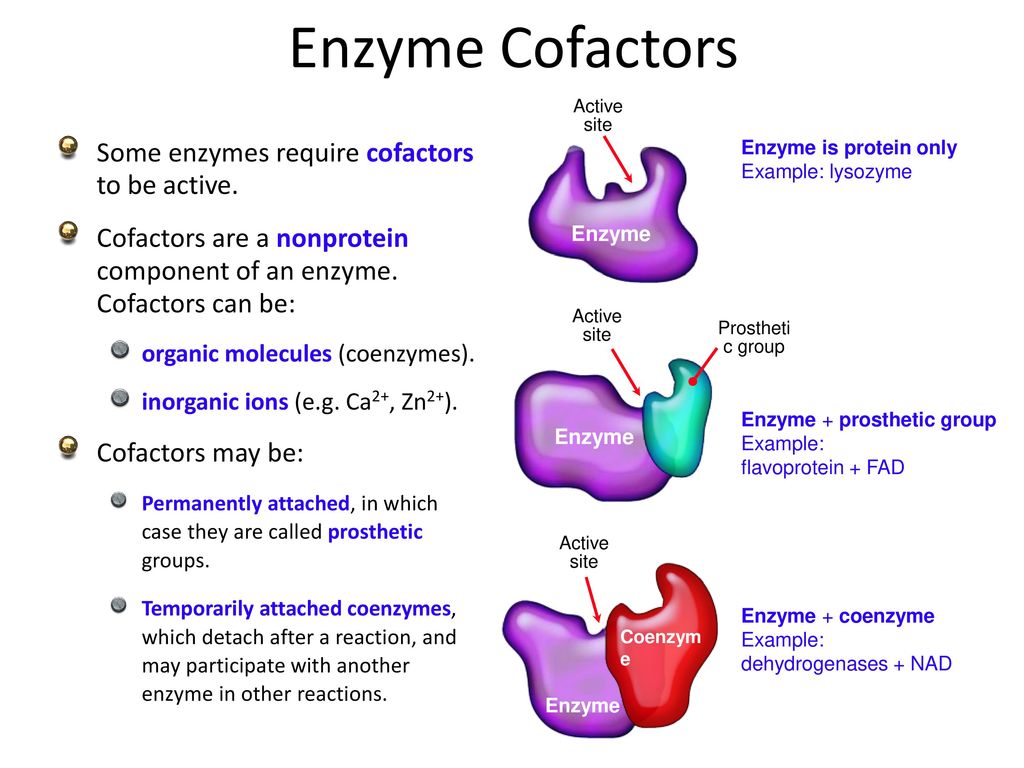
Cofactors
Enzymes extend their use of chemistry via special non-protein molecules called ‘co-factors’. Co-factors bind to the active site of a protein, and henceforth extend the range of chemistry available.
There are many types of co-factors, including:
Vitamins.
REDOX co-factors.
Organic co-factors.
REDOX co-factors, for example metals (such as Cu+ and Cu2+) can provide or take an electron in REDOX chemistry. Likewise, Fe2+ and Fe3+ – which are related by a singular electron transfer – can provide or take an electron. These metal co-factors are typical for terrestrial animals.
Organic co-factors, for example nicotinamides (such as NAD+ and NADH) are related by a difference of two electrons and one proton. Enzymes have two binding sites very close to one another; wherein NAD+ binds next to the active site for the substrate, enabling an electron and proton transfer between them. Furthermore, this enables a transfer between NAD+ and NADH. The substrate then becomes oxidised.
NAD+ and NADH REDOX Reaction
The tyrosine side-chains of the tyrosine amino acid can also act as a co-factor; it is not a co-factor in the “true” sense, however, it provides REDOX chemistry. Tyrosine’s side-chain has a phenol group that readily deprotonates to produce a phenoxide anion. It does so, because the phenoxide anion is resonance stabilised; the phenol is relatively acidic. The phenoxide anion can subsequently lose electrons to produce a phenoxyl radical.
From co-factors, we mostly get REDOX chemistry. Vitamin E has an important phenol that reacts with other species in unpaired electrons. Like the tyrosine side-chain, the vitamin E phenol readily deprotonates. The resulting phenoxide anion loses an electron to produce a phenoxal radical, and neutralises another radical – converting it into a carbocation.
REDOX chemistry is important because all biological entities relate to it.
For example, the uptake of air relies on REDOX chemistry. Air itself is unreactive, however, within our metabolism, air (oxygen) is picked up and converted to a super oxide radical anion; a very reactive species.
All sugar and carbohydrate chemistry are REDOX chemistry, relating to the conversion of aldehydes or ketones. The metabolism of fats also relies on oxidation reaction.
Plants rely on the reverse REDOX process in relation to air. Plants rely on carbon fixation to reduce oxidised carbon. In this process, carbon dioxide (CO2) first picks up two electrons and two protons across across its double bonds; becoming HCO2H. Afterwards, another equivalent of H2 is added across the remaining carbon-oxygen bond; losing water and becoming H2CO. Hydrogen addition is then used to produce the final H3COH.
Pyridoxal phosphate is another co-factor. It is used in amino acid metabolism, and commonly referred to as a “vitamin”.
The key feature of the pyridoxal phosphate is its aldehyde to pyridinian ring. It is involved in the enzymes that perform racemasation of amino acids, decarboxylation and transaminase.
The mechanism for all of these processes is relatively identical.
Racemase enzymes and pyridoxal phosphate form a Schiff-base. The pyridoxal acts as an electron sink, which attaches to amino acids. This forms a planar structure. Electrons can be restored, and opposite geometry of the structure (chirality) can be formed.
Transaminase follows the same process, however, imine can be hydrolysed to return to the original compound. Halfway through this process, the amino group of the amino acid is transferred to pyridoxal phosphate (pyridoxamine) and holds ammonia in place. Pyridoxal “pulls up” electrons through species which would otherwise be negatively unstable.
Bacteria obtain D-Alanine from L-Alanine organisms using racemases. Alanine racemase inhibitors, therefore, may be a potential antibiotic.
Beta-fluoroalanine was developed for this exact reason. When process by racemase, beta-fluoroalanine follows normal processes until protonation is supposed to occur. Instead of protonating, the electrons push out the leaving group – this produces an alpha, beta, unsaturated carboxcylic acid. This carboxcylic acid is highly susceptible to a racemase, nucleophilic attack – hence, electrons feed through the electron sink; the enzyme is irreversibly inhibited. It is a suicide-substrate inhibitor, as the enzyme commits suicide when generating the species. However, despite its effectiveness in inhibiting racemase, beta-fluoroalanine lacks specificity, and henceforth cannot be used clinically.
Enzymes achieve catalysis due to the active site cleft present in proteins.
Protein Active Site
The most important aspect of catalysis is species proximity – the closer the species are to one another, the better.
The rate of reaction of two species can be given by the equation:
rate = k[A].[B]
Typically, reagents without an enzyme have a nanomolar concentration and small rate. When together, however, the enzyme protein brings about the correct orientation of the species for a productive collision; bringing about a higher concentration and larger rate.
Enzymes function perfectly at the “diffusion control limit”. This is what enables enzymes to provide simultaneous acid-base catalysis.
Triosephosphate Isomerase
Triosephosphate isomerase (TIM) is the “perfect enzyme”. It is involved in glucose metabolism, and is present in high concentrations in muscle tissue, where it acts to generate ATP rapidly.
In glucose metabolism, glucose is broken down to the two substrates: glyceraldehyde-3-phosphate (G3P) and dihydroxyacetone phosphate (DHAP). This is an energetically unfavourable process, as it is inefficient and consumes ATP.
G3P is then converted to pyruvate, producing 2 ATP molecules and 1 NADH for each 3 carbon unit. The rate of this reaction, however, depends on the G3P concentration.
Through an equilibrium between G3P and DHAP in muscle tissues, TIM efficiently catalyses storage in a diffusion controlled conversion. This allows twenty-three times the amount of energy precursor than usual to be stored.
Equilibrium
The equilibrium functions at a rate determined by which the substrates can diffuse through the reaction medium to get to the enzyme.
TIM is so perfect that when artificially mutated, it mutates back to perfection, with a catalytic number of 10^8 – 10^9/M/s.
The mechanism for the reaction catalysed by TIM involves the formation of an enediol intermediate. The catalytic residues glutamate and histidine are involved in general acid-base catalysis.
General acid-base catalysis is involved in a majority of enzymatic reactions, wherein the side chains of various amino acids act as general acids or general bases. General acid-base catalysis involves a molecules besides water that acts as a proton donor or acceptor during the enzymatic reaction. It facilitates a reaction by stabilising the charges in the intermediate state, through the use of an acid or base.
Nucleophilic and electrophilic groups are activated as a result of the acid/base, and causes the reaction to proceed.
An example of acid-base catalysis is peptide hydrolysis by chymotrypsin.
Chymotrypsin
Chymotrypsin is involved in cleavage of amide bonds in peptides. It hydrolyses the peptide bond which connects the carboxyl group of one amino acid to the amino group of another. Key parts of the enzyme include serine, aspartic acid and histidine residues. The enzymatic reaction occurs in a step-wise process, generating a catalytic triad to improve the nucleophilic properties of serine and water.
Chymotrypsin uses a histidine residue and aspartic acid as a base catalyst. The histidine-aspartate deprotonate serine to increase its nuclephilicity. The serine then attacks the substrate’s carbonyl carbon, forming a tetrahedral intermediate. Then, an acyl group bounds to an intermediate, forming an acyl-enzyme intermediate. One product diffuses away at this time.
In carbonic anhydrase, the histidine residue helps the removal of hydrogen ion from the water molecule to generate OH- and strengthen its nucleophilic property. Once done, the water molecule attacks the acyl-enzyme, forming another tetrahedral intermediate, forming another product which diffuses away.
An oxyanion hole stabilises the tetrahedral intermediate anion formed during proteolysis and protects substrate’s negatively charged oxygen from water molecules. It stabilises the tetrahedral intermediate in chymotrypsin.
Enzymes can also attach to substrates “poised to strike”. Upon binding to a substrate, enzymes use binding energy to distort or strain the molecule on binding towards the transition state for the reaction, increasing energetic favourability.
Enzymes also work through binding in a reactive conformation. For example, phenylalanine ammonia lyase catalyses the the elimination of ammonia, and conversion of phenylalanine to cinnamic acid; putting phenylalaline amino acid into the food cycle. This reaction occurs in an “anti-configuration” environment as the hydrogen and amino group are lost, and henceforth biases the reaction.
An operon is essentially an assembly line of regulatory DNA genes, controlled by a region called the ‘promoter’. The regulatory DNA sequences act as binding sites for regulatory proteins, that promote or inhibit transcription.
Operons are quite efficient, however, if a singular mutation occurs at any point on the operon, the entire polycistronic pathway can be impacted. Operons can also struggle to take advantage of environmental changes; all genes are activated when the promoter is active.
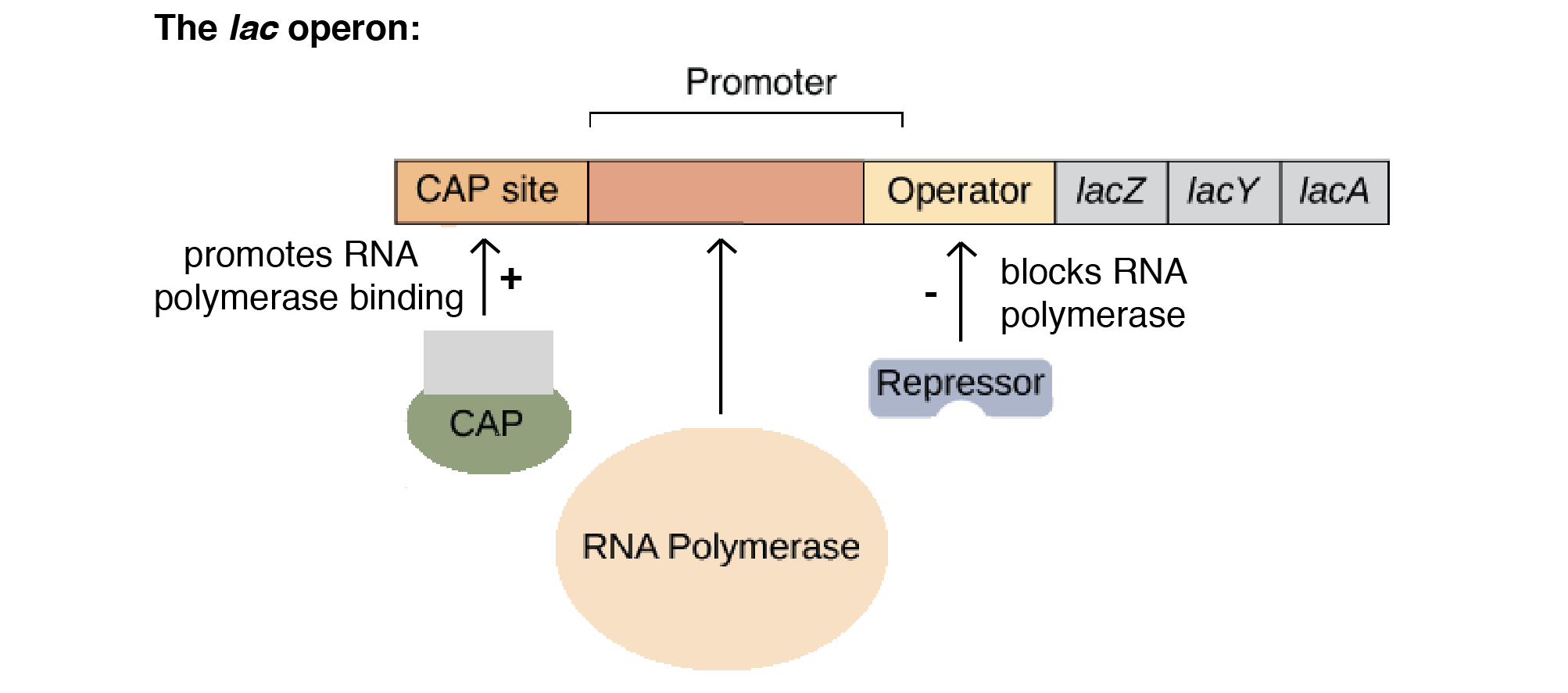
The lac Operon
A common example of an operon is the lac operon.
The lactose, or lac, operon is most commonly found in the bacterium Escherichia coli (E. coli). The lac operon refers to a cluster of three structural genes that each encode for proteins involved in lactose metabolism. These genes are ‘lacA’, ‘lacY’ and ‘lacZ’. LacZ and lacY are essential for the utilisation of lactose by E. coli.
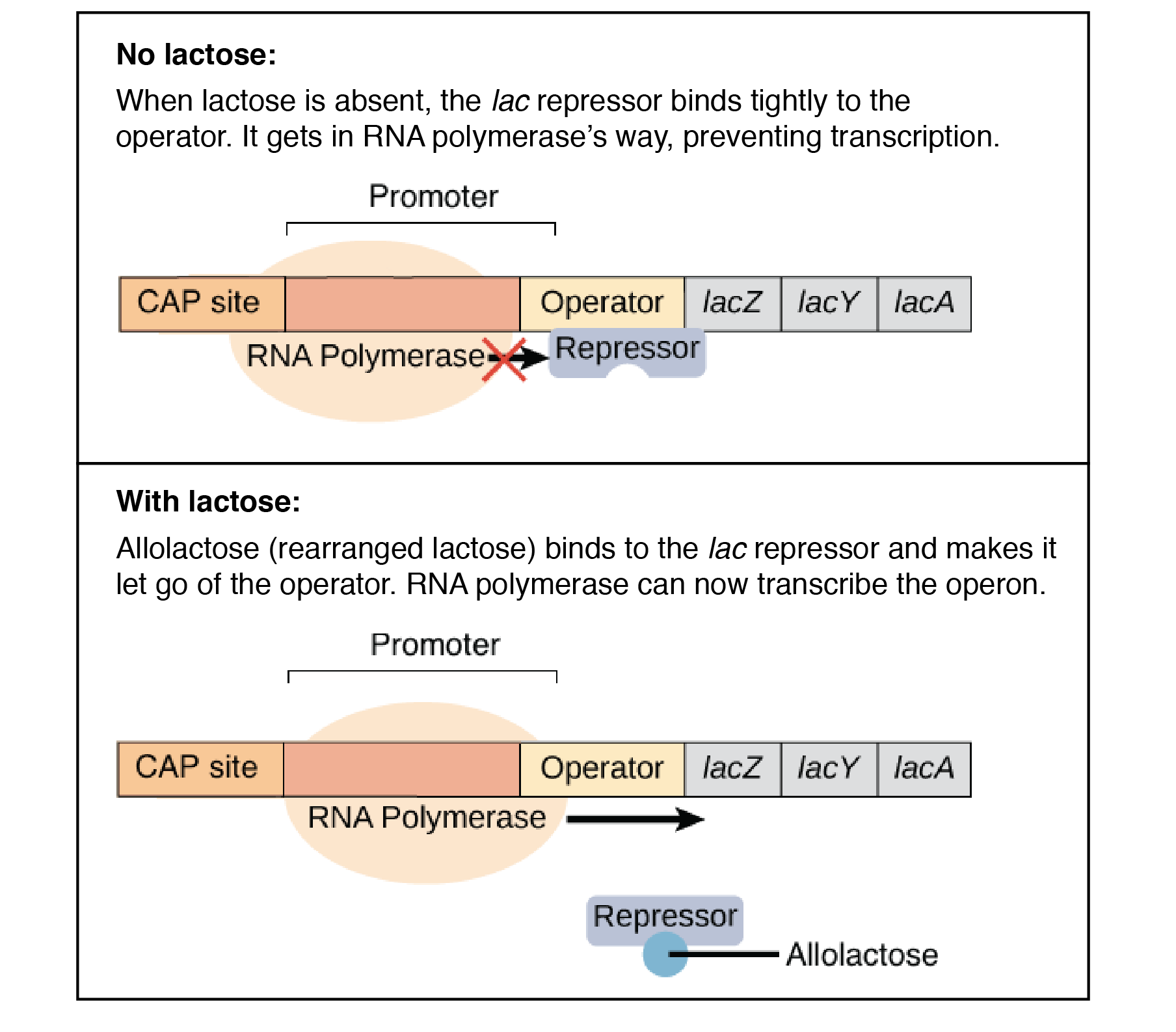
The lac operon is a negative, inducible system. When no lactose is present, a repressor binds to the operator – preventing transcription. In the presence of lactose, allolactose binds and inactivates the lac repressor. This allows RNA polymerase to bind to the lac operon – enabling transcription.
It is important to note that a repressor binds to the operator, which prevents RNA polymerase from binding and transcription occurring. This is negative control.
An activator encourages polymerase to bind to the promoter. This is positive control.
The lacA gene encodes for lactose transacetylase; an enzyme that transfers an acetyl group from acetyl-CoA to galactosides.
The lacY gene encodes for lactose permease; a transmembrane protein that facilitates the movement of lactose across the phospholipid bilayers that surround all cells and organelles via active transport. When glucose is present, lactose permease is not produced – hence, lactose cannot be transported into the cell.
The lacZ gene encodes for β-galactosidase; a bacterial enzyme that catalyses the breakdown of lactose into its component simple monosaccharides, glucose and galactose. The synthesis of β-galactosidase is activated when glucose levels are low, and lactose is present. When glucose is low, β-galactosidase and lactose fit together. Once together, a change in conformation of the enzyme occurs. This new conformation causes bond strain between the monosaccharides, until eventually the bond breaks, and glucose and galactose dissociate from the enzyme to provide energy to the bacterial system. β-galactosidase synthesis stops when glucose levels are sufficient.
Lactose permease actively transports lactose into the cell. Following this, β-galactosidase breaks down the lactose into its components galactose and glucose. β-galactosidase also converts lactose into allolactose, then converts the allolactose into galactose and glucose.
Catabolite repression regulates the lac operon via positive control. It is the process of glucose repression. There is an inverse relationship between glucose and cyclic-AMP (cAMP); when cellular glucose levels are high, cAMP is low, and vice versa. When cAMP is present, a catabolite activator protein (CAP) binds to the lac operon promoter, facilitating the binding or RNA polymerase to the promoter, leading to enhanced transcription of the operon’s genes.
The lac Operon
Another common operon example is the tryptophan, or trp, operon. The trp operon is an example for negative repressible transcription.
When tryptophan is low, the inactive regulator protein (repressor) does not bind to the operator, enabling transcription. However, when tryptophan is high, the repressor and tryptophan bind together, then bind to the operator. This prevents transcription from occurring.
Attenuation is a mechanism for reducing expression of the trp operon when levels of tryptophan are high. Rather than blocking initiation of transcription, attenuation prevents completion of transcription. The attenuation of the trp operon works through a mechanism that depends on coupling (the translation of an mRNA that is still in the process of being transcribed).
The trp RNA is able to form a hairpin. When sections 1 and 2 pair, and 3 and 4 align, transcription is terminated. However, when 2 and 3 bind, transcription still occurs. This determines which regions pair up.
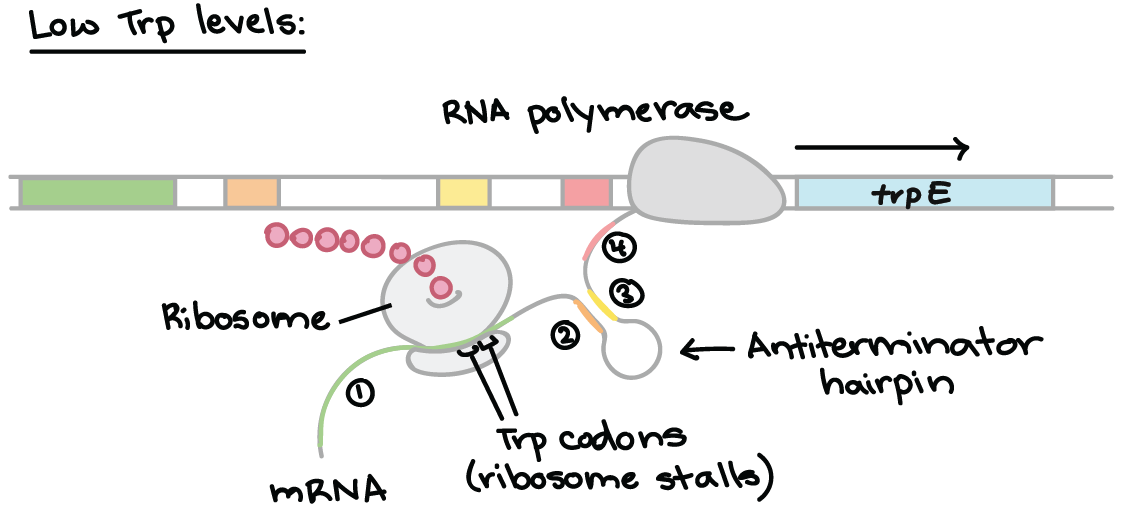
Low Tryptophan
When tryptophan levels are low, the ribosome stalls at the trp codons in region 1. Region 2 then is not covered by the ribosome, where region 3 is transcribed. When region 3 is transcribed, it pairs with region 2 – the attenuator never forms and transcription continues.
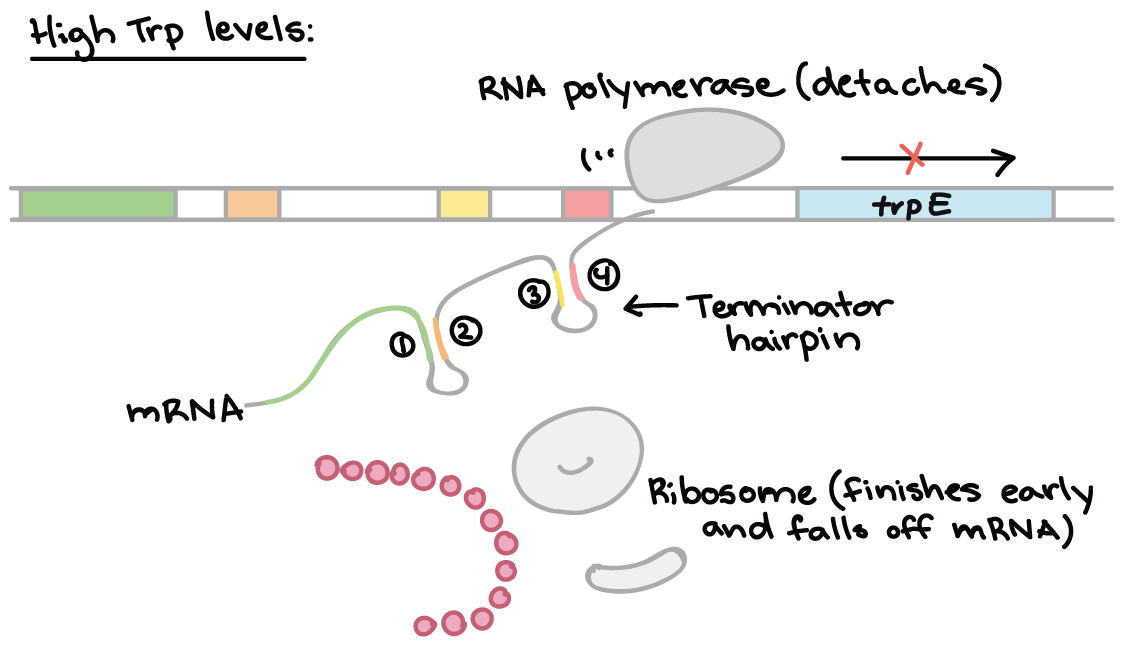
High Tryptophan
When tryptophan levels are high, RNA polymerase begins transcribing DNA – producing region 1 of the 5′ UTR. A ribosome binds to the 5′ end of the 5′ UTR, and translates region 1 while region 2 is being transcribed.
RNA polymerase transcribes region 3. The ribosome does not stall at the trp codons, because tryptophan is abundant.
The ribosome covers part of region 2, preventing pairing with region 3. Region 4 is transcribed and pairs with region 3, producing the attenuator that terminates transcription.
The definition of a gene is “the entire nucleic acid sequence that is necessary for the synthesis of a functional gene product (polypeptide or RNA)”.
Prokaryotic vs Eukaryotic Gene Structure
The gene structure of prokaryotes are essentially the “blueprint” for the bigger picture; the overall genome dictates what the prokaryote will look like and how it will function.
The genetic content of a prokaryote includes:
A circular chromosome.
A circular plasmid,
A nucleoid,
Genes organised as operons, polycistronic transcription.
Prokaryotic genomes are part of one large circular DNA molecule.
Prokaryotic Genome
The bacterial genome includes one origin of replication. Just one origin of replication is required to initiate DNA replication – removing this origin would mean there is no propagation of DNA.
Most bacterial species contain circular chromosomal DNA, usually a few million base pair long. A few thousand different genes are interspersed throughout the genome; intergenic regions are regions that are not genes.
Genes are organised into operons and transcribed as a polycistronic mRNA. An operon consists of a set of genes encoding proteins participating in the same metabolic pathway.
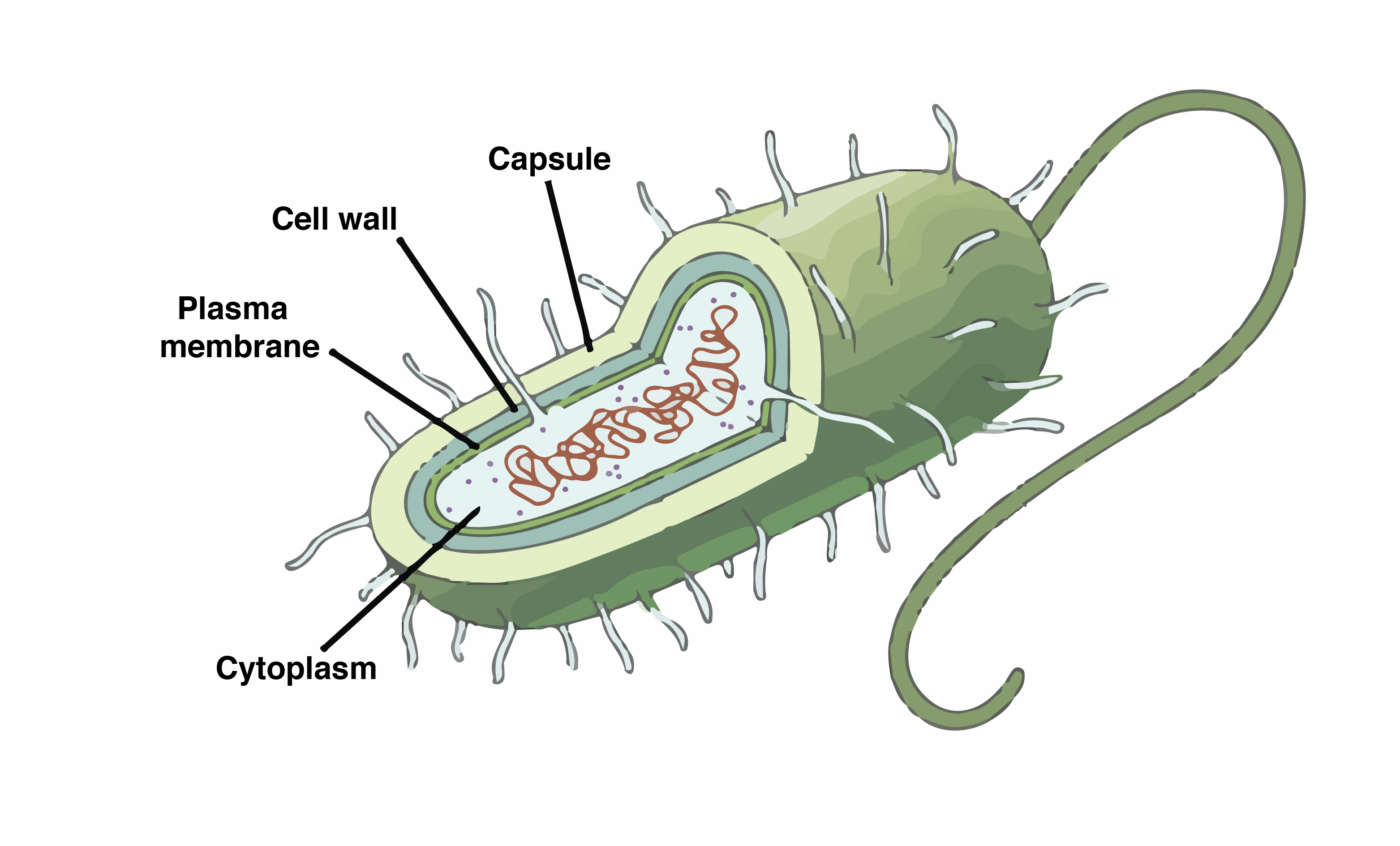
Prokaryotic Cell
Prokaryotes lack cell organisation. Unlike eurkaryotes, DNA is not complexed with histones. There is a relatively lesser amount of DNA in prokaryotes than in eukaryotes.
Most prokaryotes contain two types of DNA: bacterial chromosomes provide the main source of information, whereas plasmids are non-essential. Plasmids replicate independently, contain fewer genes, are not essential for survival, and can integrate with the chromosome.
Genes from plasmids can integrate into chromosomes. This means you can change bacteria from non-pathogenic to pathogenic, by adding plasmids with particular virulence factors. Information henceforth flows between plasmids and bacteria.
Prokaryotes multiply via binary fission; asexual reproduction. This means prokaryotes can replicate at an extremely rapid pace – for example, E. coli can replicate every 20 minutes.
A common question those in science wonder is: “what is the difference between biochemistry and chemical biology?”.
Well, the difference is this: biochemistry typically focuses on the chemistry of biology, whereas chemical biology focuses on manipulating chemistry to solve biological problems.
Chemical biology can become complicated quite quickly, so it is important to understand and be comfortable with the basic biochemical processes within our body. Having the foundations of chemical biology down pact is valuable to a science student focusing on medicine, forensics, chemistry or biology. The foundations of chemical biology are also particularly handy for those wanting to sit the GAMSAT; the graduate medical entry examination that is held in Australia and the United Kingdom.
In this blog, we are going to discuss these major topics:
DNA (deoxyribonucleic acid) is the hereditary material found in almost all organisms. The function of DNA is determined by its structure.
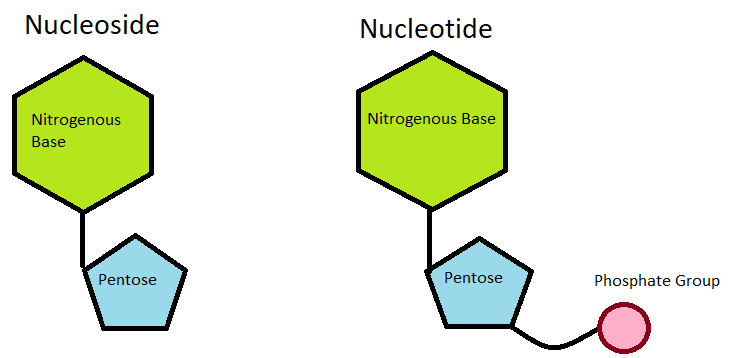
The information of DNA is stored as a code made up of for chemical bases: adenine (A) and guanine (G) (the purines), and cytosine (C) and thymine (T) (the pyrimidines). Each of these bases make up the important DNA monomer unit, the nucleotide: which consists of a phosphate, pentose sugar and base.
Nucleoside vs Nucleotide
A common phrase people hear about DNA is that it is a “double helix”. This refers to the fact that DNA is made up of two complementary strands that are tightly wound together. DNA is twisted in this way due to hydrogen bonds forming between the bases (C-G, A-T), and ring polarisation of said bases. Van der Waals forces stabilise this twisting, via the sum of Van der Waals radii (3.4Å), enabling DNA to adopt the lowest energy state possible.
Separating the two strands of DNA, however, causes supercoiling. The term ‘supercoiling’ is an expression of the strain on that strand.
Supercoiling of DNA is an important biological process, that is regulated by topoisomerases and gyrases (specific DNA enzymes).
Topoisomerase and Gyrase Supercoiling a DNA Monomer
By supercoiling DNA, it can be easily compacted and utilised in further processes, such as DNA replication or transcription. By tightly wounding DNA, large amounts of it can be packed into the nucleus. This allows DNA to be safely stored but remain easily accessible.
A simple way to imagine this is by picturing an elastic band.
Elastic Band Supercoiling
By twisting and rolling the elastic band between your finger and thumb, the band shrivels and tightens, and becomes much smaller; compact. Imagine we have a small box we need to fill with these bands – it would be much easier to fill the box with compacted elastic than the original, large elastic. Even though it has changed shape, it is still an elastic band. It still provides the same information – it is just smaller. That is what DNA supercoiling is doing in the nucleus.
In a human cell, approximately six feet of DNA must be packaged into a nucleus with a diameter less than a human hair. To do this, nucleosomes are used.
Nucleosomes are the basic packing unit of eukaryotic DNA.
Nucleosome Structure
Each nucleosome is an octamer (polymer of eight molecules) of two copies of each of the nucleosomal histones, H2A, H2B, H3 and H4. 147 base pairs of DNA are wrapped almost twice around the histone octamer. Histone H1 binds outside of the nucleosome. Any non-histone proteins form a chromatin scaffold.
The nucleosomes are then arranged like beads on a string. They are repeatedly folded in on themselves to form a chromosome; a DNA molecule with genetic material of an organism.
Lipids are important macromolecules within our body. When people hear the word “lipid”, they typically think of fats. However, lipids are actually a diverse group of compounds, which include oils, hormones and fats.
Glycerol
Glycerol is typically the backbone for complex lipids, such as glycerides. Glycerol is colourless, odourless and typically has a sweet taste to it. It is a three-carbon alcohol and a major “acceptor” for fatty acids.
It is important to understand that fatty acids are typically unreactive molecules. They are happy to do their own thing, lounge around and have a good time. Our bodies don’t necessarily like this though – fatty acids can be quite useful. So, we add a molecule named coenzyme A to make fatty acids a bit more… snappy.
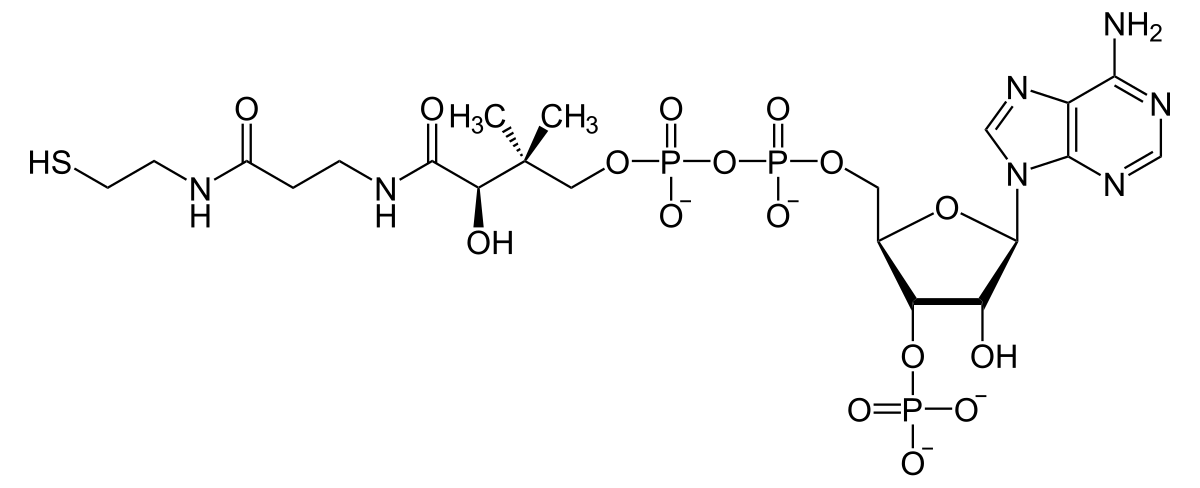
Coenzyme A
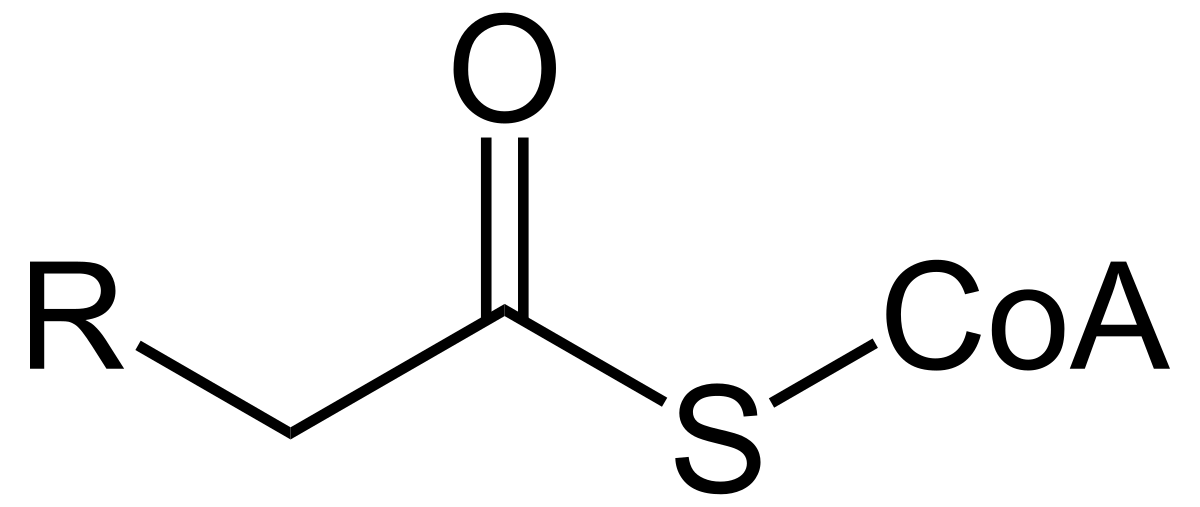
Coenzyme A contains a highly reactive thiol group named acyl CoA.
Acyl CoA
When we use coenzyme A, acyl CoA is added to the carboxyl group of fatty acids. This enables fatty acyl CoA to react with the alcohols on glycerol to generate di and triglycerides.
Di and triglycerides are both particularly important molecules. However, today we are going to focus on diglycerides.
Phospho-Glycerolipid
Diglycerides are particularly important for the synthesis of phospholipids and acting as signalling molecules.
A phospholipid is a lipid made of glycerol, two fatty acid tails, and a phosphate-linked head group. These head groups can be: serine (-), inositol (-), or neutral with both positively and negatively charged coups: cholin, ethanolamine.
All phospholipids are amphipathic. This means they have both hydrophilic (water-loving) and hydrophobic (water-hating) parts. In this molecule, the hydrophilic component is the polar end – aka the phosphate and ‘x’ head group. The negative charge of the phosphate makes it water loving. The hydrophobic component is the non-polar end – aka the two fatty acid tails. A way to remember this is to imagine oil in water – they do not mix, no matter what you try. You can shake it, heat it, freeze it, but they will not mix. Fatty acids will not mix with water.
It is important to note:
Saturated fatty acids are localised to C-1.
Unsaturated fatty acids are localised to C-2.
The ‘X’ site (head group) attach at C-3.
Phospholipid structure is classified according to the head group and acyl chain composition. Thus, they are named phosphatidylserine (PS), phosphatidylcholine (PC), phosphatidylethanolamine (PE), phosphatidylinositol (PI).
Sphingolipid
Another important lipid are the sphingolipids. The backbone of sphingolipids is sphingosine, which is analogous to the glycerol moiety in phospholipids.
It is important to note:
A fatty acid chain is attached via amide linkage to the NH2 molecule on C-2.
The polar head group is attached at C-1.
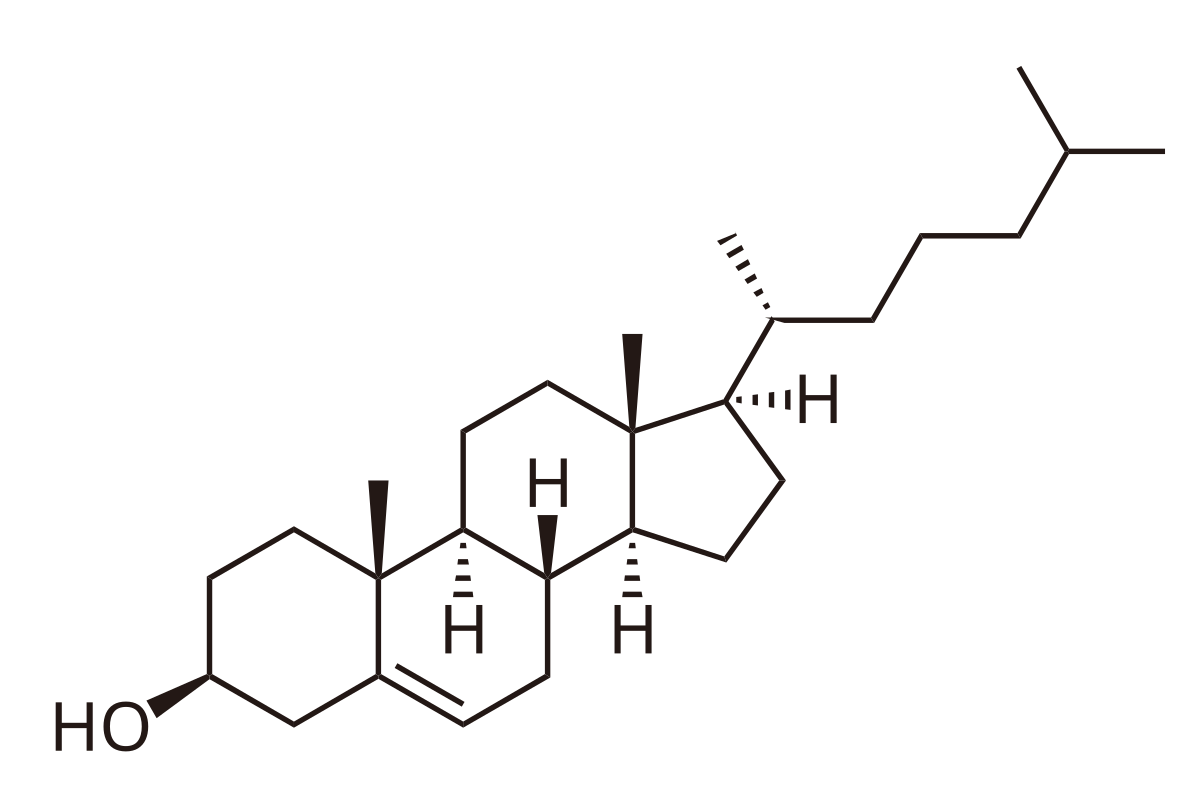
Cholesterol
Yet another important lipid is cholesterol.
Cholesterol is a 27 carbon compound built from units of acetyl-CoA (not to be confused with acyl CoA!). Cholesterol is a highly rigid, hydrophobic molecule. Its ampiphillicity arises from the hydroxyl moeity.
Each lipid structure within our bodies are determined by the physical and chemical properties of their constituents. Micelles and liposomes form spontaneously in aqueous solutions. Cholesterol intercalates into either structure.